谷歌研究人員發(fā)布的一篇新論文在人工智能與計(jì)算領(lǐng)域投下了一枚“重磅炸彈”。該論文提出的關(guān)鍵技術(shù),能夠?qū)⒋笮驼Z(yǔ)言模型推理過(guò)程中占用大量?jī)?nèi)存的KV Cache壓縮高達(dá)6倍。這一突破性進(jìn)展不僅直接影響了相關(guān)內(nèi)存技術(shù)公司的股價(jià),更被業(yè)界廣泛視為可能開(kāi)啟一個(gè)類似“DeepSeek時(shí)刻”的新紀(jì)元,為大數(shù)據(jù)信息處理服務(wù)的效率與可及性帶來(lái)革命性提升。
一、 核心技術(shù):理解KV Cache與內(nèi)存瓶頸
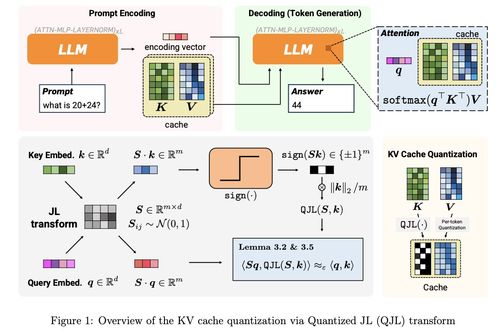
在大型語(yǔ)言模型(如GPT、PaLM等)的推理過(guò)程中,為了生成連貫的文本,模型需要記住之前所有生成的token的上下文信息。這部分信息通常以“鍵-值”(Key-Value,簡(jiǎn)稱KV)對(duì)的形式緩存在內(nèi)存中,稱為KV Cache。隨著生成長(zhǎng)度的增加,KV Cache所占用的內(nèi)存會(huì)線性甚至平方級(jí)增長(zhǎng),成為制約模型處理長(zhǎng)文本、降低推理成本和提高吞吐量的主要瓶頸。尤其是在需要同時(shí)處理大量用戶請(qǐng)求的云服務(wù)場(chǎng)景下,內(nèi)存消耗直接關(guān)聯(lián)著硬件成本和能源消耗。
二、 谷歌的突破:6倍壓縮如何實(shí)現(xiàn)?
谷歌論文的核心在于提出了一種高效、無(wú)損或高保真的KV Cache壓縮算法。其思路并非簡(jiǎn)單粗暴地丟棄信息,而是通過(guò)創(chuàng)新的方法(可能涉及稀疏化、量化、結(jié)構(gòu)化修剪或動(dòng)態(tài)內(nèi)存分配等高級(jí)技術(shù))來(lái)識(shí)別并保留對(duì)后續(xù)生成最關(guān)鍵的那部分上下文信息,同時(shí)極大地壓縮或高效表示冗余或次要的信息。
關(guān)鍵優(yōu)勢(shì)可能包括:
1. 高壓縮比:在保證模型輸出質(zhì)量(困惑度)基本不變或僅有極小損失的前提下,實(shí)現(xiàn)高達(dá)6倍的內(nèi)存占用減少。
2. 計(jì)算友好:壓縮與解壓過(guò)程對(duì)計(jì)算開(kāi)銷的增加極小,不會(huì)顯著拖慢推理速度。
3. 即插即用:該方法可能無(wú)需對(duì)預(yù)訓(xùn)練好的模型進(jìn)行重新訓(xùn)練或微調(diào),可直接應(yīng)用于現(xiàn)有模型的推理部署中,降低了應(yīng)用門檻。
三、 市場(chǎng)震動(dòng):“內(nèi)存股價(jià)”背后的邏輯
論文成果一經(jīng)披露,立即在資本市場(chǎng)引發(fā)連鎖反應(yīng),部分內(nèi)存芯片及存儲(chǔ)解決方案供應(yīng)商的股價(jià)應(yīng)聲下跌。這背后的邏輯清晰而直接:
- 需求預(yù)期變化:如果未來(lái)所有大模型服務(wù)提供商都采用此類技術(shù),那么部署相同規(guī)模的AI服務(wù)所需的內(nèi)存硬件總量將大幅減少,直接削弱了市場(chǎng)對(duì)高端內(nèi)存(如HBM)長(zhǎng)期增長(zhǎng)的需求預(yù)期。
- 成本結(jié)構(gòu)重塑:AI推理的成本中心可能從昂貴的內(nèi)存硬件向其他方面轉(zhuǎn)移,改變了產(chǎn)業(yè)鏈的價(jià)值分配。
四、 開(kāi)啟“谷歌的DeepSeek時(shí)刻”:大數(shù)據(jù)處理的新范式
“DeepSeek時(shí)刻”在此處是一個(gè)類比,意指像DeepSeek公司以其高性價(jià)比模型引發(fā)行業(yè)關(guān)注一樣,谷歌此項(xiàng)技術(shù)可能從基礎(chǔ)設(shè)施層面觸發(fā)AI應(yīng)用普及的拐點(diǎn)。
對(duì)大數(shù)據(jù)信息處理服務(wù)的影響將是深遠(yuǎn)的:
- 服務(wù)成本大幅降低:云服務(wù)商能夠以更低的硬件成本提供大模型API服務(wù),最終可能降低企業(yè)及開(kāi)發(fā)者的使用門檻。
- 長(zhǎng)上下文處理成為常態(tài):內(nèi)存瓶頸的突破使得模型能夠更經(jīng)濟(jì)地處理超長(zhǎng)文檔、長(zhǎng)對(duì)話歷史和多輪分析任務(wù),極大地拓展了在金融分析、法律文檔審閱、長(zhǎng)篇內(nèi)容生成等領(lǐng)域的實(shí)用邊界。
- 實(shí)時(shí)性與吞吐量飛躍:在固定內(nèi)存預(yù)算下,服務(wù)器能夠同時(shí)處理的用戶請(qǐng)求數(shù)(吞吐量)顯著增加,提升了高并發(fā)場(chǎng)景(如智能客服、實(shí)時(shí)翻譯)的服務(wù)質(zhì)量。
- 邊緣部署成為可能:壓縮后的模型對(duì)內(nèi)存的要求降低,使得在邊緣設(shè)備(如手機(jī)、物聯(lián)網(wǎng)終端)上運(yùn)行更強(qiáng)大的模型變得更為可行,推動(dòng)AI真正走向無(wú)處不在。
五、 展望與挑戰(zhàn)
盡管前景光明,但該技術(shù)走向大規(guī)模應(yīng)用仍需面對(duì)一些挑戰(zhàn):壓縮算法在不同模型架構(gòu)和任務(wù)上的普適性、極端壓縮下輸出質(zhì)量的長(zhǎng)期穩(wěn)定性、以及與現(xiàn)有推理軟件棧的集成優(yōu)化等。這也將促使整個(gè)行業(yè)更加關(guān)注算法創(chuàng)新與硬件協(xié)同設(shè)計(jì),而不僅僅是追逐參數(shù)規(guī)模的競(jìng)賽。
總而言之,谷歌的這項(xiàng)研究不僅僅是一項(xiàng)技術(shù)優(yōu)化,它更像是一把鑰匙,有可能打開(kāi)高效、普惠AI計(jì)算時(shí)代的大門。它迫使行業(yè)重新審視AI算力的消耗模式,并將加速大數(shù)據(jù)信息處理服務(wù)向更高效、更廉價(jià)、更強(qiáng)大的方向演進(jìn)。未來(lái)的AI服務(wù),或許將不再如此“健忘”和“昂貴”,而這正是技術(shù)突破帶來(lái)的最直觀的福祉。